A Transformer for Physics Models
Traditional physics solvers are held back by the way computation balloons as you add resolution and dimensions.
Simulating a 64x64 grid requires 4096 operations while a still modest 128x128 grid requires 16,384 operations.
In 3D this problem is even worse as and .
Simulating a meaningfully sized physical system requires massive simplifications and training AI physics models with traditional transformer architecture is only possible with regrettably small grid sizes and time lengths.
The Trim Transformer was built to train generative AI physics models. Its multi-linear attention computes
in time, replacing the quadratic cost of soft-max attention with attention that stays linear in sequence length.
So the Trim Transformer simulates a 64x64 grid in 128 operations, a 128x128 grid in 256 operations, and a 128x128x128 3D simulation in only 384 operations. Whew!
An exponential reduction in compute unlocks a new world of modeling complex, high-dimensional systems such as
- Detailed molecular bonding for medicine research
- Global climate and weather modeling
- Semiconductor and battery material design
- Nuclear fusion plasma modeling
- Gravitational waves and quantum mechanical systems
- Low latency autonomous vehicle pathing
The implementation mirrors torch.nn.TransformerEncoder, so swapping it into an existing PyTorch pipeline is a one-line change.
Example: Navier-Stokes
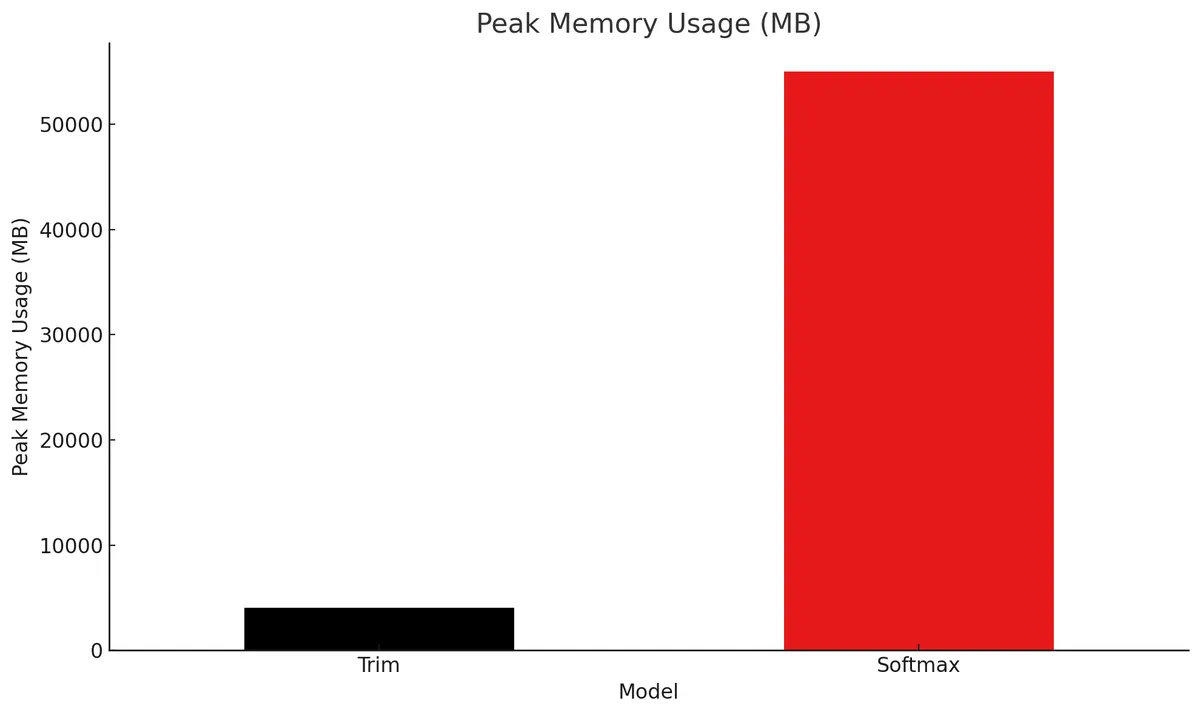
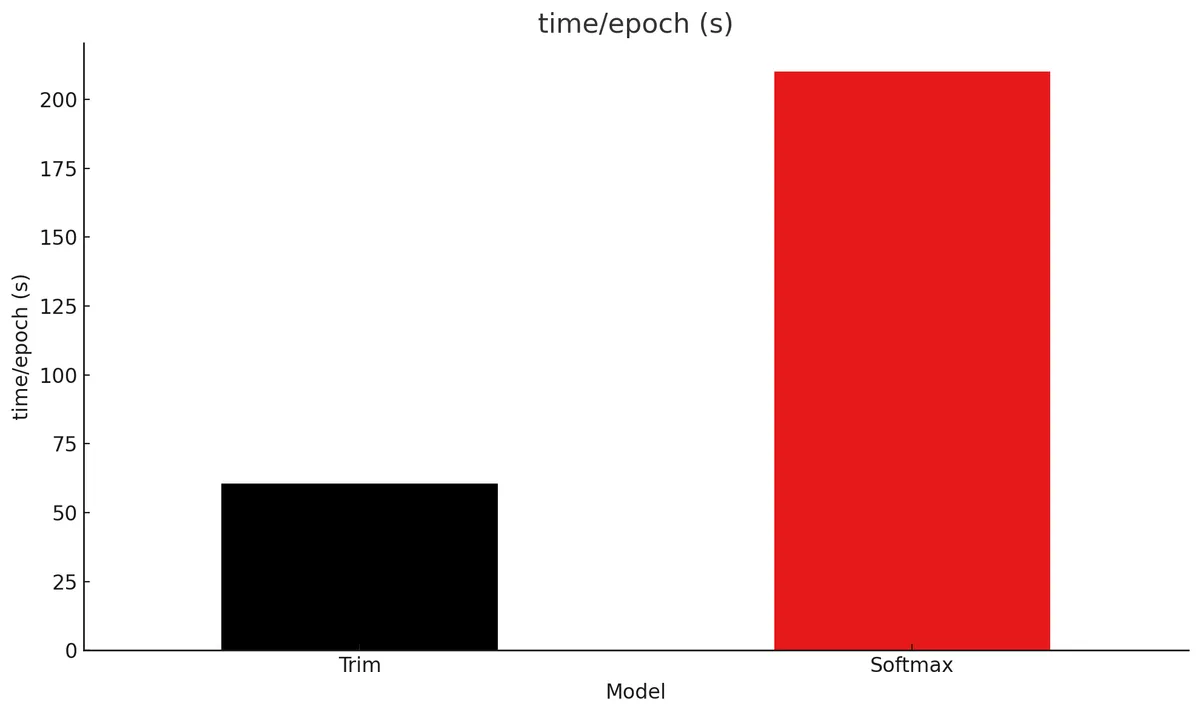
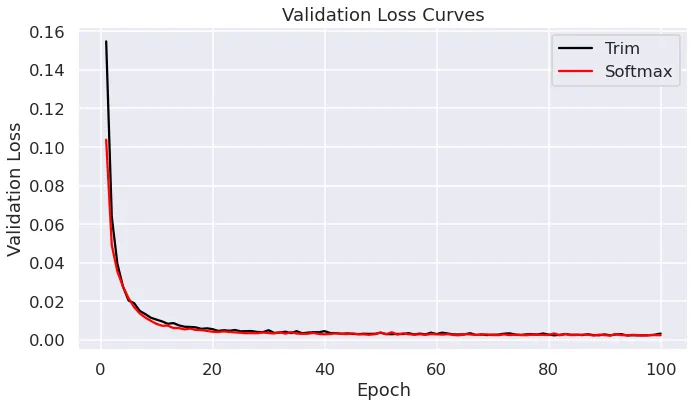
Below are some benchmark plots demonstrating model performance and resource usage on the Navier-Stokes dataset from Fourier Neural Operator:
The Trim Transformer achives more than 90% reduction in memory usage compared to a standard PyTorch transformer using softmax attention and 3.5x faster time per epoch while maintaining very similar validation loss. As grid size and sequence length increase these gains become even more drastic.
You can install the Trim Transformer with
pip install trim-transformer
or find it on GitHub.
We'll be showcasing a variety of use cases over the next few weeks so sign up to stay in the loop.